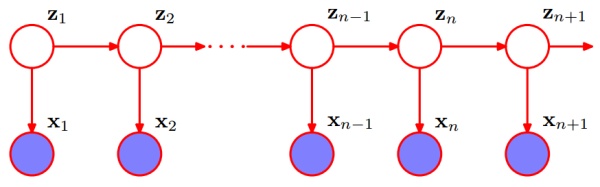
why it could be defined as below:
,represent probability of length = states, only when , it would be counted into , random variable
Define constant matrix
where, for short: write
size() = ,
is probability distribution sequence of th state,
is probability distribution sequence,
is probability distribution sequence,
In P(z,theta), is observation value;
In , is random variable;
Thus
Goal
thus we get
So
Here
So
if is continuous
if m is discrete
Only is known,
for example is random variable, then is another variable, then
then
期望最⼤化算法,或者EM算法
where
Where
- is arbitrary distribution for
- 概率分布的⼀个泛函, 函数
- 概率分布的⼀个泛函, 函数,KL散度 of ,
So
notice: is fixed, are variables,转而用 替代;
调整法
- fix , change [E步骤]
- fix , change [M步骤]
ignore influence of in
set
get
update
Conclusion
因为1,2中 均上升;
且1中
2中
- 所以在一个循环1,2中下界
consider
Use to delete variables,
is fix observation value;
is [probability distribution] random variable, is random variable
is [probability distribution] random variable of [probability distribution] random variable
where
其中, 因为 分别为已知、固定 在 M步骤
为常数,是期望, 大小
为常数,是期望, 大小
下面求解
subject to
with Lagrange method:
where ,
if is discrete,
, ,
So
To sum up
How to calculate
为常数,是期望, 大小
为常数,是期望, 大小
similarly get:
so
其中 is constant
So if is obtained, we could get
How to obtain
for , initial value:
Recurrence relation
for , last initial value:
Recurrence relation
To sum up
Then
because are so small
we divide into 2 part
define
the other way
so
thesame
the
then
其中 is constant